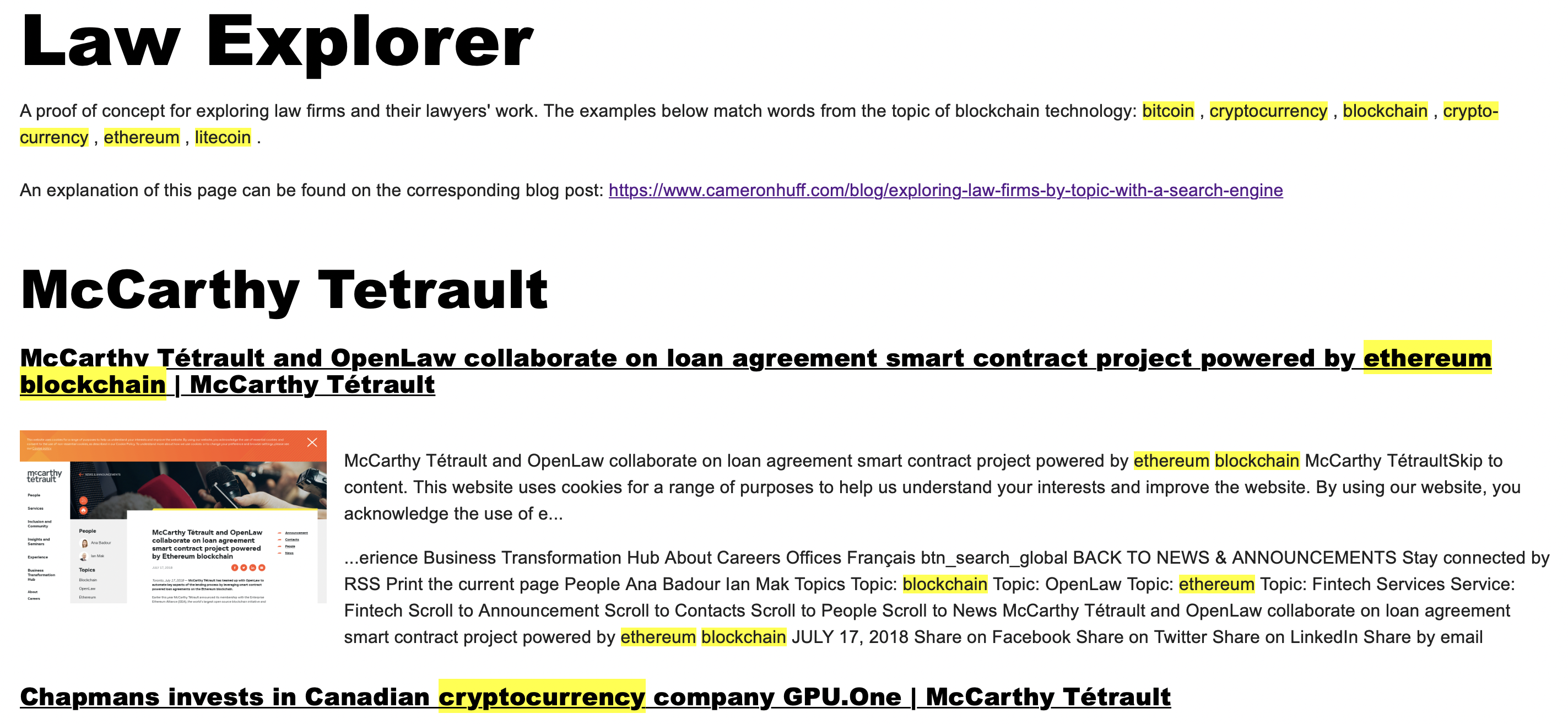
Law firms generate large amounts of quality legal content that's often hard to find. They're not always the best at search engine optimization and the content is often not really designed to be easily consumed (it's for a niche audience). One of the main purposes of this content is to show who knows what they're talking about, because it's better to have an article showing that than a brief line in the bio of a lawyer saying it. But how can someone find which lawyers are good at what? How can that content be exposed? Are there ways of synthesizing this content or making it more readily available to the people it's designed for and others?
I've recycled a web crawler I wrote to index the pages of a few Canadian law firms as a proof of concept. The result can be seen here: https://www.cameronhuff.com/blog/_assets/gf/law_firm_blockchain_topics_sept22_2021.html. Ten articles are chosen from each firm, based on matching a few blockchain-related keywords. I think a similar approach could be used for other specialty areas. These articles are great resources for lawyers to learn from, and to help discover which firms have the practice groups that can support your clients.
Please Reach Out
Do you think this approach has merit? Interested in talking about ideas for how search engines could be used to help improve law or improve the practice of it? Please send me an email: addison@cameronhuff.com.
Crawler Details
The web crawler is a custom system that I developed to start from a home page and move down breadth-wise. It uses a Chromium browser underneath to load pages like a user would, and take screenshots as it goes.
For this particular application, the compressed text is searched using regular expressions and then merged. The content is cleaned up a bit and some basic scoring is done on the results. It renders to a static page. The results shown above are from this crawler running for a few days, during which it identified around 48000 unique pages. It's designed to regularly recrawl the pages, with recrawl time decreasing with depth. Documents and PDFs are converted to text automatically.
Here's a blog post about an earlier version of this system that I made for securities regulators: https://www.cameronhuff.com/blog/making-a-search-engine-gorilla-find/index.html.
Screenshot