
Why Make A Search Engine?
There are many reasons to make a search engine but I have a specific need in mind: knowing about government changes. My law practice requires me to know about regulatory changes or legal developments in the area of virtual currency to within a day or two. Shouldn't every lawyer know about relevant changes as soon as they happen? The rest of this blog post explains my attempt to do this over the last year in my spare time on weekends, why this is an incredibly hard problem, and finally: some pointers for anyone who wants to try to do this. Below is a screenshot of the search engine I made.
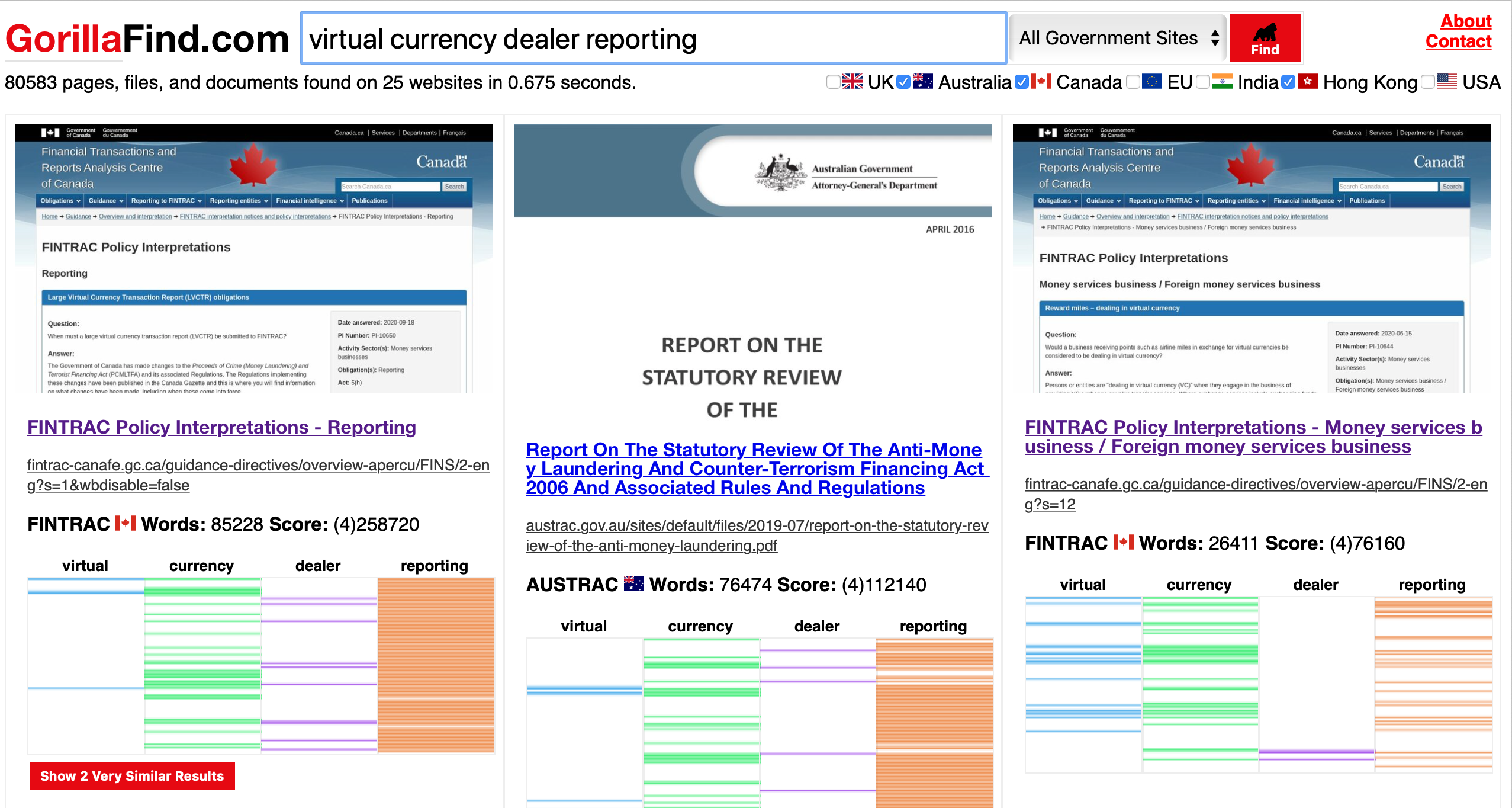
What Exists and My Past Businesses
Amazingly, in 2020 this is still very much a "pull" not "push" system in which the burden is on those who are regulated to know about changes, but the people who regulate don't take steps to communicate those changes. One possible solution is to have dedicated indexing programs like OntarioMonitor.ca (which I made in law school but sold to a partner) that are designed for a specific site and a specific regulatory context. A more general version is the next legaltech business I made along this same idea: global-regulation.com to index the world's laws and translate them into English. But I've always wanted a general solution, a general purpose search engine that can constantly watch for relevant changes, and that does so in the same way as a human using a web browser (not a crawler like Apache Nutch). A "professional" search engine. But I also want to use a search engine that doesn't know what I'm searching for, which can be achieved in part by locally hashing search query terms (it works!).
What's a Professional Search Engine?
The startup space is littered with failed search engines that could not compete with Google. The idea of making a search engine is obvious but the "how" is not.
There are several ways to reduce the scope of this project to make it more feasible: 1) only government sites 2) only selected sites. By using only government sites many problems of SEO, relevant, and spam are solved. By using only selected sites there is an opportunity to categorize information according to the ministry/regulator that makes it easier to search than a general purpose search engine like Google. Beyond reducing scope, there are many choices to be made about how, and my own project answers this is in every way with: in the cheapest way possible. The reason for this is that cost is the killer of Google challengers. The Internet is big. Very, very big. And because of the way that websites work (e.g. recursive links and duplicate auto-generated content with minor variations), a site does not have clear boundaries as to size. Picking cost as the guide post means making some sacrifices but it also simplifies the design.
GorillaFind.com, the site I set up to explore this concept, shows how I envision a professional search engine.
How Does It Work?
From a user perspective, the search system works like the diagram below.
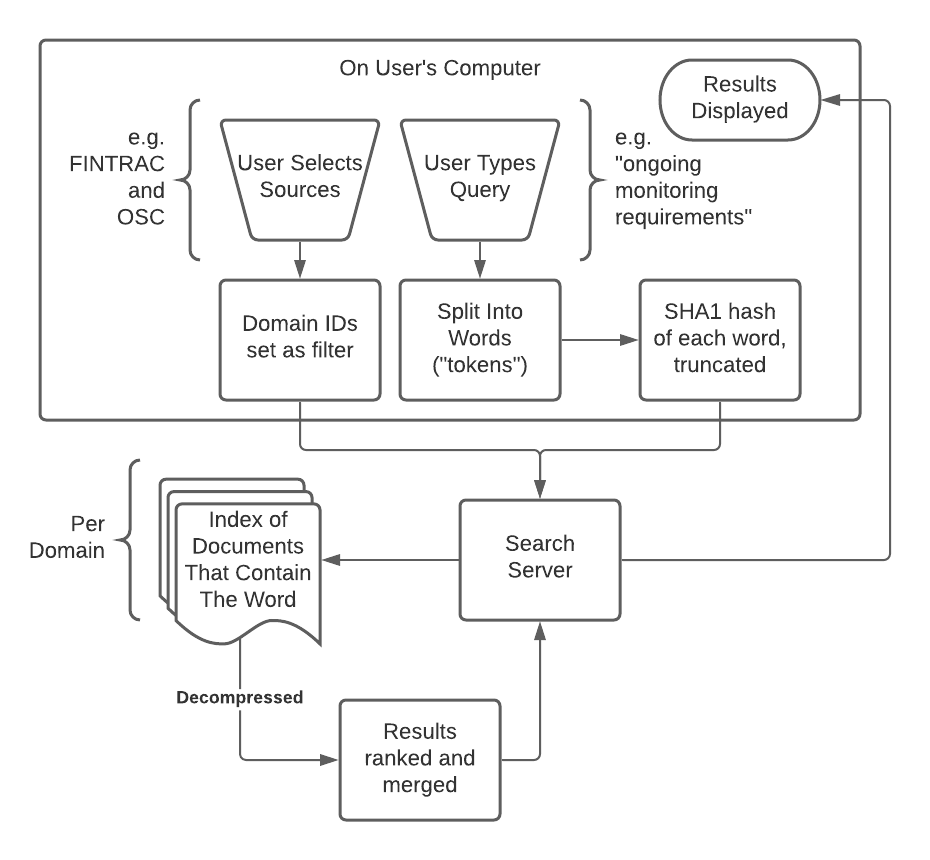
But how was the data generated in the above system? The indices were created by a backend system that is the heart of a search engine.
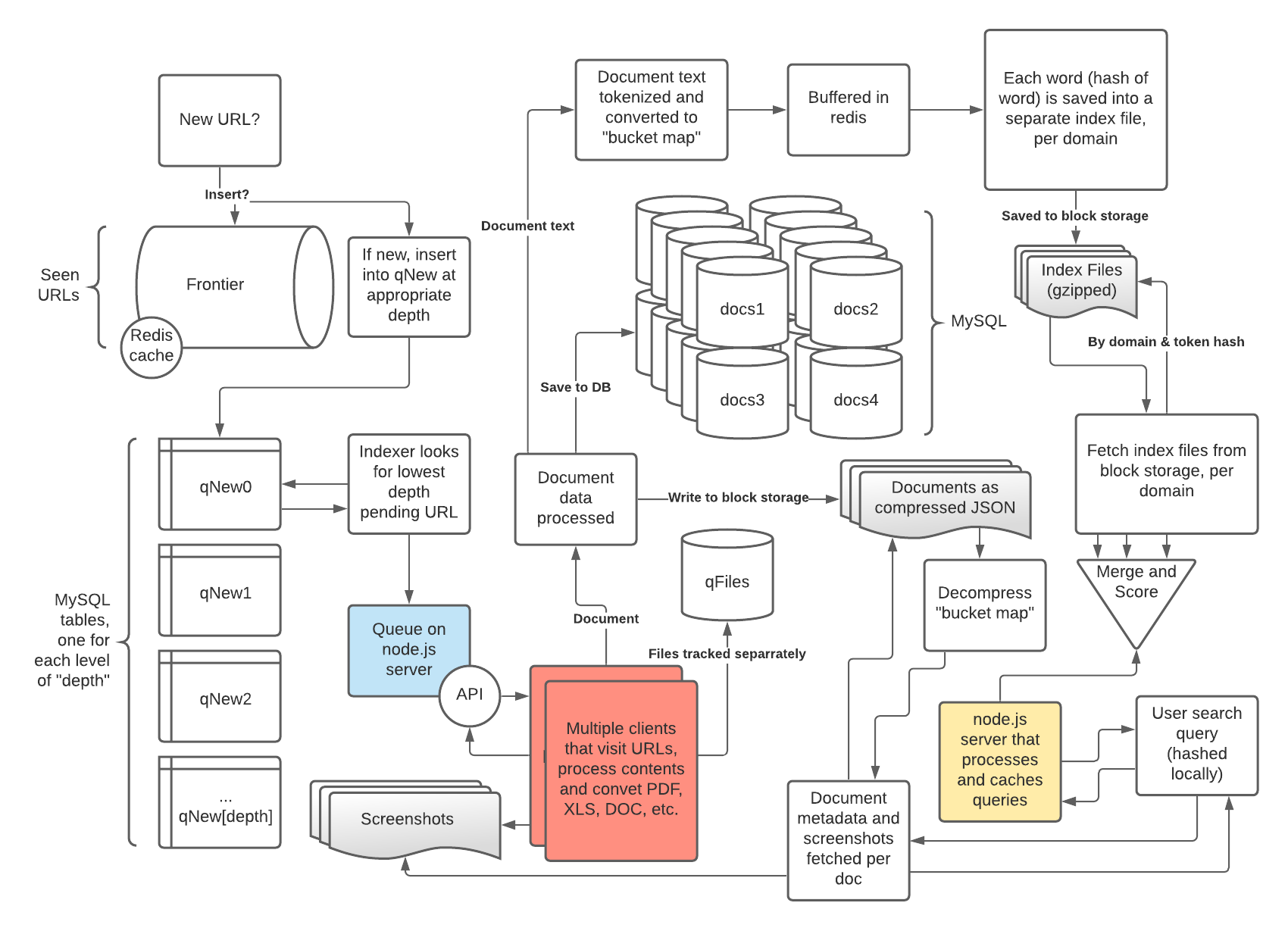
The diagram above is a basic overview of how GorillaFind.com works on the backend. The system operates on three different types of servers: 1) hub 2) fetch 3) public site. "Hub" is the main file storage, batch processing and search server. "Fetch" is the downloading clients that run Google Chrome browsers to visit pages, take screenshots and convert files to text. The public site is gorillafind.com which runs the website but also has a simple node.js server that sends requests to the appropriate hub, caches queries and generally interfaces with the rest of the system. The system today runs on four Digital Ocean servers, with three being their cheapest $5 USD per month, and the hub being a $10 USD/mo server. A hub server can comfortably house 10-50 domains, depending on the size and query capacity targetted.
Fetching
The fetch servers have several components:
1. Querying the hub for the next URL to visit by calling the API
2. Fetch a page using Chromium (open source Chrome) in headless mode, controlled by Playwright (the successor t Puppeteer maintained by Microsoft), driven by a node.js script, managed by a program that sends successful downloads to the hub.
3. File conversion using libreoffice (.docx and .xls), pdfbox (.pdf), and exiftool to read metadata.
Hub
The hub servers have several components:
1. Many APIs for reading and writing
2. Backend processes that run periodically for tasks like writing files to disk, adding to indices, and loading new items into the queue (for the fetch servers to download). The hub also manages recrawling of pages already visited.
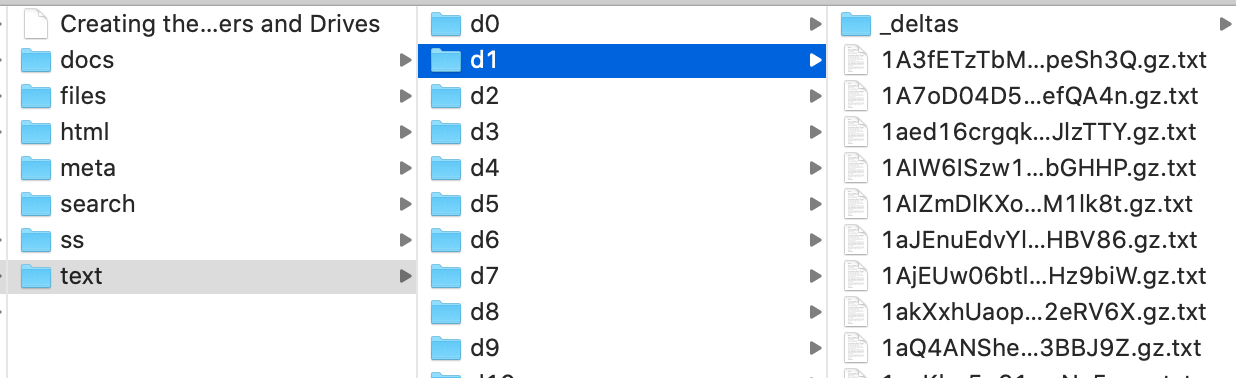
3. A file system (using the btrfs file system because it handles small files better) with most files organized by domain (a numeric identifier). Files are stored on an expandable block storage volume (which on DigitalOcean and other providers costs about $0.10 USD per month per gigabyte).
4. A queue that holds the URLs that have the highest download priority, per domain. Here is the node.js code for the queue server: https://www.cameronhuff.com/blog/_assets/files/gf-queue-nodejs.zip.
5. Various scripts for managing the hub such as for adding and removing domains.
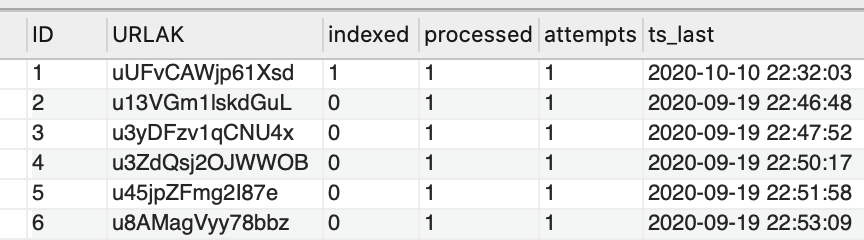
6. A large MySQL database of all queued URLs, arranged by depth, where depth 0 is the home page and each "click" further away from the home page is one higher in depth. Each URL is stored according to a truncated sha1 hash of the URL (specifically, the origin URL, not the visited URL which might be different if there is a redirect).
7. A large MySQL database of known documents, but just the document ID and other metadata because the actual document information is stored in a compressed JSON file on disk (block storage).
Public Site
The user experience for GorillaFind.com is lacking because my real goal was building a solid underlying system, to be used for flexible purposes. It would be great if websites had APIs to allow programmatic access, which could be done through a search engine like this.
A Visual Map of a Page
With GorillaFind.com, I didn't set out to copy Google. That's not feasible. But it is possible, by developing a system from the ground up, to make something different than Google. One of the core features of GorillaFind.com is that it shows the distribution of the search words on each page of the results. The screenshot below shows what this looks like to the user.
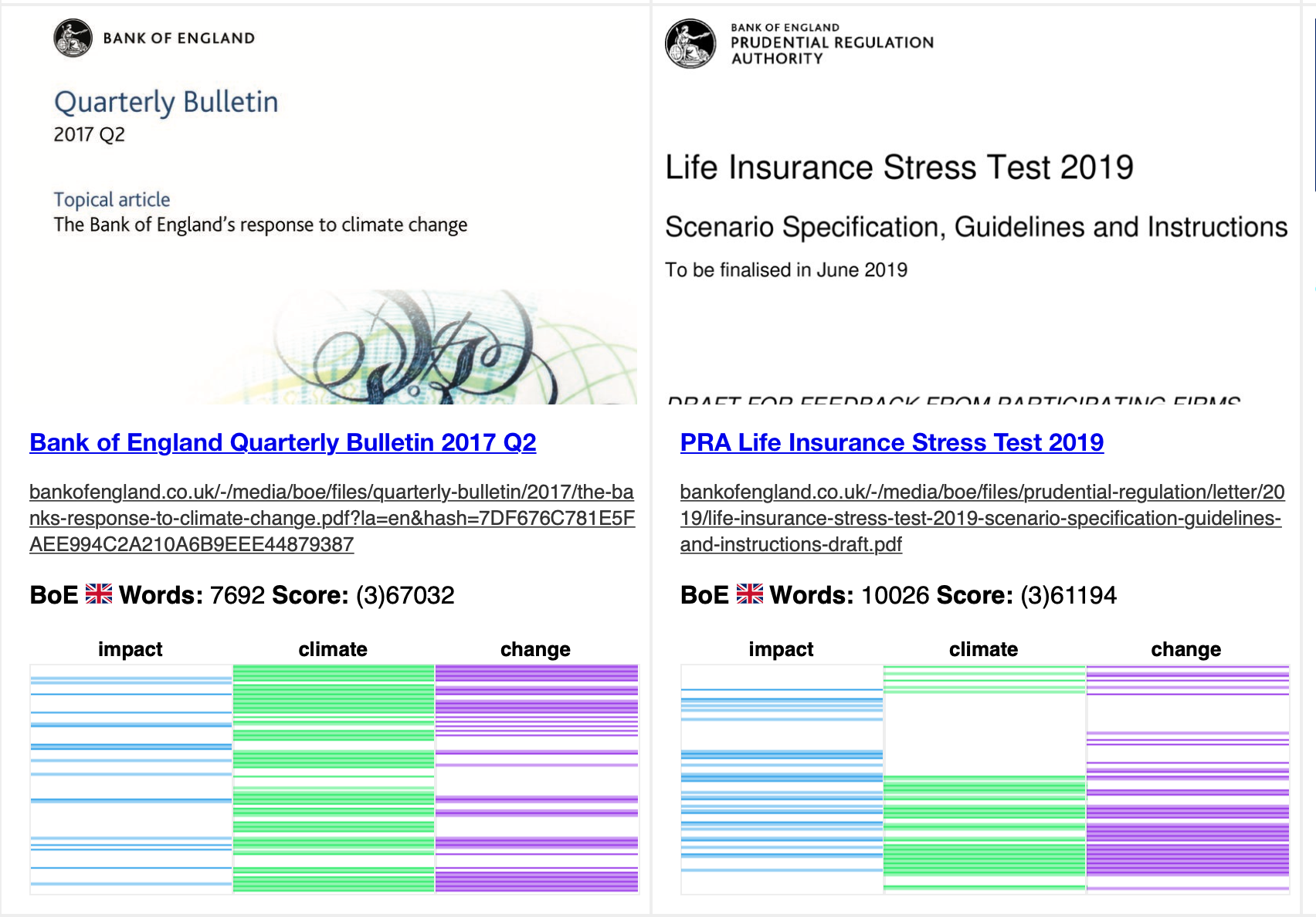
By showing the pages in a document to the user on the search screen, someone can much more easily navigate large reports and government pages that are quite different in character from what non-professionals search for. Despite the words shown in the legend, the words are actually stored as hashes on the server, and then the hashes are read back to the user who's computer knows which words they originally searched for (because of the hash). I hope one day this kind of visual search becomes more common.
Technologies Used
I try to keep my projects as simple as possible, and use standard languages/tools. Here are the key technologies used:
MySQL, redis, PHP, node.js, bash, libreoffice, pdfbox, Playwright, Chromium, imagemagick, and btrfs.
Lessons Learned
1. Use private networking for traffic between components. I originally intended to use a hybrid cloud approach using GCP and other providers but the bandwidth cost is far too high. In my first month, I spent $90 USD on bandwidth using GCP on a simple database with just a few tens of thousands of indexed pages. This is cost prohibitive. Public networking ought to be minimized to downloading web pages.
2. Compress screenshots carefully. Screenshots are a major part of the disk requirement.
3. Use "block storage" (network-attached flash memory storage) to store indices instead of RAM because it's 1/25 the cost and only barely slower for this kind of application. It's more than an order of magnitude cheaper than the old Google approach of RAM-based indices that I originally set out to copy.
4. Carefully distinguish between URLs that are perceived (i.e. displayed on a site) vs. actual URL that results from following the link.
5. When dequeueing URLs, be careful to dequeue the one with the lowest depth and lowest number of attempts. Depth first dequeuing is a necessity because many sites are essentially endless. Depth is a very important property of a page.
6. Store pages using delta compression. Here's the PHP library that does this in GorillaFind and can achieve very significant page size savings: https://www.cameronhuff.com/blog/_assets/files/gf-Delta.class.php. The encoding process works by creating a "map" of which new lines correspond with old lines, and then a set of new lines and where they appear. The map can be then be used to reconstruct the file using the set of changes and the original file. Delta encoding text and HTML files can save as much as 90% of the size.
7. Don't store something if it's already stored, by addressing content using hashes. This ensures that a file overwrite won't create new content (and waste more disk space.)
8. Sequeuntial-ish integer data can often be stored using offsets instead of the actual number to achieve significant file size savings. For example: 8901, 8902, 8903 can be more efficiently be stored as: 8901, +1, +1. For every page that GorillaFind reads, it stores all the words and where they appear in the document into a "bucket map". Imagine a page that has 100 "buckets", where bucket 0 is at the start of the document and bucket 99 is at the end. The bucket map for the words "ABC" and "XYZ" looks like: {"ABC": [1, 2, 4],"XYZ": [0, 3, 4, 5]}, where in that example, ABC occurs in buckets 1, 2, 4 and XYZ occurs at 0, 3, 4, and 5. This kind of data compresses very well using offsets, where for XYZ it would read 0, 2, 1, 1. And in my real world testing of this, strings of repeated offsets like 1,1,1 often occur and can replaced with a code like !3 instead for even greater savings. A (poorly commented) PHP library that does this on GorillaFind can be seen here: gf-buckets.inc.php.
9. Hash collisions are far more common than you'd expect due to the "birthday problem". The solution is to choose hashes that are shorter than sha1 (to save space) but not so short that there'll be collisions. But this problem also extends to how files are stored because filesystems use hashes, which limits the maximum number of files per folder when using a filesystem like ext4. (Use btrfs instead of ext4 for part of the solution to that problem.)
10. Always use an object for storing a URL because raw URLs that are read from webpages often have issues. It's important to wrap a URL in an object that does tests on the URL to make sure it's valid and throws errors appropriately. Here's a PHP class that does this: gf-URLO.class.php. Validate everything.
11. Use redis to cache data. A cache is essential and MySQL (or another database, I started with mongodb) isn't meant for that. But also use redis for basic queues, for which a system like this needs several to achieve good throughput.
12. Use APIs to connect components across system boundaries rather than using file access or database access directly. It makes the system more modular so it's easier to adapt to architectural changes and decreases mistakes.
13. Think carefully about where data is stored. Some data needs to be in RAM, some can be stored temporarily on disk on a VM or in a database, some needs to be on block storage, etc.
14. Bandwidth charges make even cheap servicse like B2 (S3-compatible object storage) expensive.
15. DigitalOcean.com is cheap and has a Toronto data center for local storage of data.
16. sha1 hashes can be done using webcrypto API but MD5 can't.
17. Redis BITFIELD command can be used to store information in bitmaps that can be very efficient memory-wise.
18. Using block storage to store indices is cheap but limits the throughput of the system. GorillaFind operates at about 1 query per second (without caching) for reasonably complex multi-domain searches.
19. Storing data in tables where the table name is a part of the index (such as docs1, docs2, etc.) can make a lot of sense and be much faster than a large table with an index for the field. It's a partitioning strategy that makes the system easier to understand too.
20. Websites are not designed to be crawled. Proper crawling, that is respectful (i.e. not too many pages loaded per hour), thorough without being overly thorough, and adjusted according to how frequently site content appears to change, is incredibly hard.
21. Study academic articles and search engine company presentations, even old ones (pre-2010) to understand how to design a search engine. The basics are pretty well-known and there's no need to re-invent the wheel. Much of the improvements over the last 10 years in search engines is due to machine learning and other advancements that aren't really changes to the core mechanics of how a search engine works.
22. The distribution of words in a document is just as important as the word count, and maybe more so.
23. Search terms can be locally hashes on the user's computer and sent to the server to see if there are pages that have that term, without exposing the term itself to the search engine. This works on GorillaFind.com using sha1 hashes of the search terms, and indexing the words by hash (not by word). This makes certain machine learning methods not work, and there are good reasons why Google wouldn't do this, but it's possible to make a more privacy-aware search engine, and I think government websites should adopt this to minimize the amount of information disclosed by citizens searching for laws, reports, or other government information. Google may be nosy, but government websites don't have to be!
24. Downloading and indexing a website with hundreds of thousands of pages takes a long time if you are want to crawl a site politely (i.e. one page per minute).
25. Base conversion for large numbers in Javascript can be inaccurate. Be careful about integer precision. Here's example Javascript code (that will run on most browsers) that can take a string from a user and convert it to base62: gf-text_to_base62_example.js. I hope someone reads this and saves themselves three hours of trying to figure out why a SHA-1 hash generated in a browser does not match another library's output.
The Most Important Resource: Time
I knew making a search engine would be hard and have been working on GorillaFind.com partly for that reason. It's fun to take on something that's so challenging you're not sure if it's possible. Making a search engine is possible, but incredibly hard, and quite expensive. Running 50 financial and securities regulator sites on GorillaFind.com takes $25 USD/mo of servers and $20 USD/mo of block storage for over 750,000 indexed pages. At around $1 USD/mo that's quite affordable, but the real cost is time. This has taken me around 200 hours of work on weekends and some nights over the last year, and it's just scratching the surface of what it would take for a production service like this. But it's possible to do, which is rather amazing considering how complicated a proper search engine like Google or Bing is, and the hundreds of people who work on them.
In 2020, making even a simple search engine is beyond what a single person can do and would really require a small team of dedicated people to do it right. It's not the cost of the servers (if you design it to be as cheap as possible), it's the cost of the time to make it.
If you are curious about making your own search engine or want to avoid some of the pitfalls I've encountered, please reach out: addison@cameronhuff.com. This has been a fun weekend hobby that's taught me a lot and I'm happy to share.